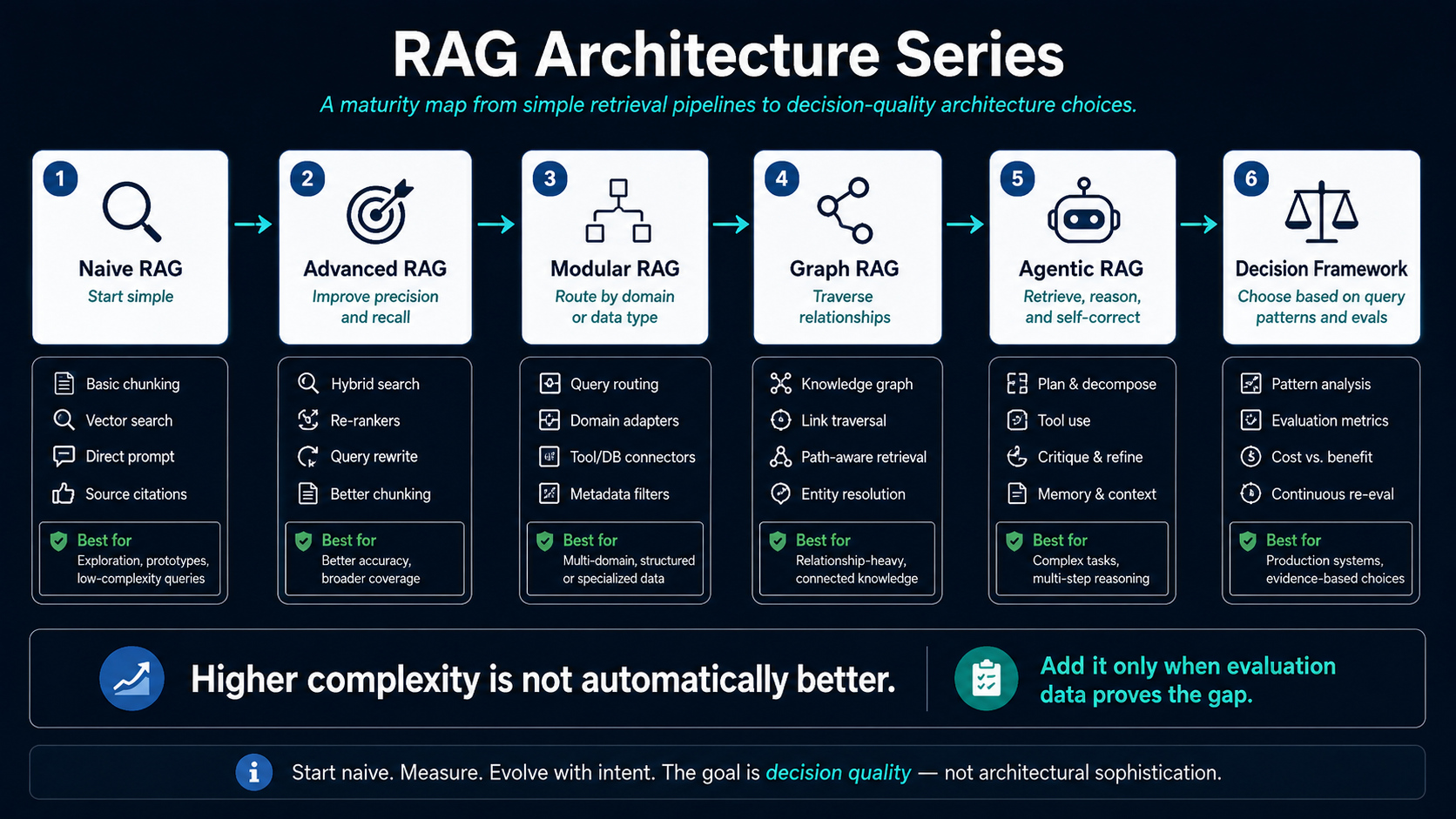
A good RAG system is not defined by retrieval alone. It is defined by the architecture around it: query understanding, context selection, evidence quality, evaluation, governance, and production behaviour. This series breaks down the major RAG patterns with architecture diagrams and engineering reasoning for each. You will not just learn what each pattern is; you will learn when it earns its complexity, what it costs to add, and how to choose the right design using evaluation signals instead of architectural hype.
Click to enlarge