RAG often begins with a simple idea: retrieve relevant information, give it to a language model, and generate a grounded answer. That basic loop is easy to demonstrate. Building a RAG system that remains accurate, secure, traceable, and useful in production is harder.
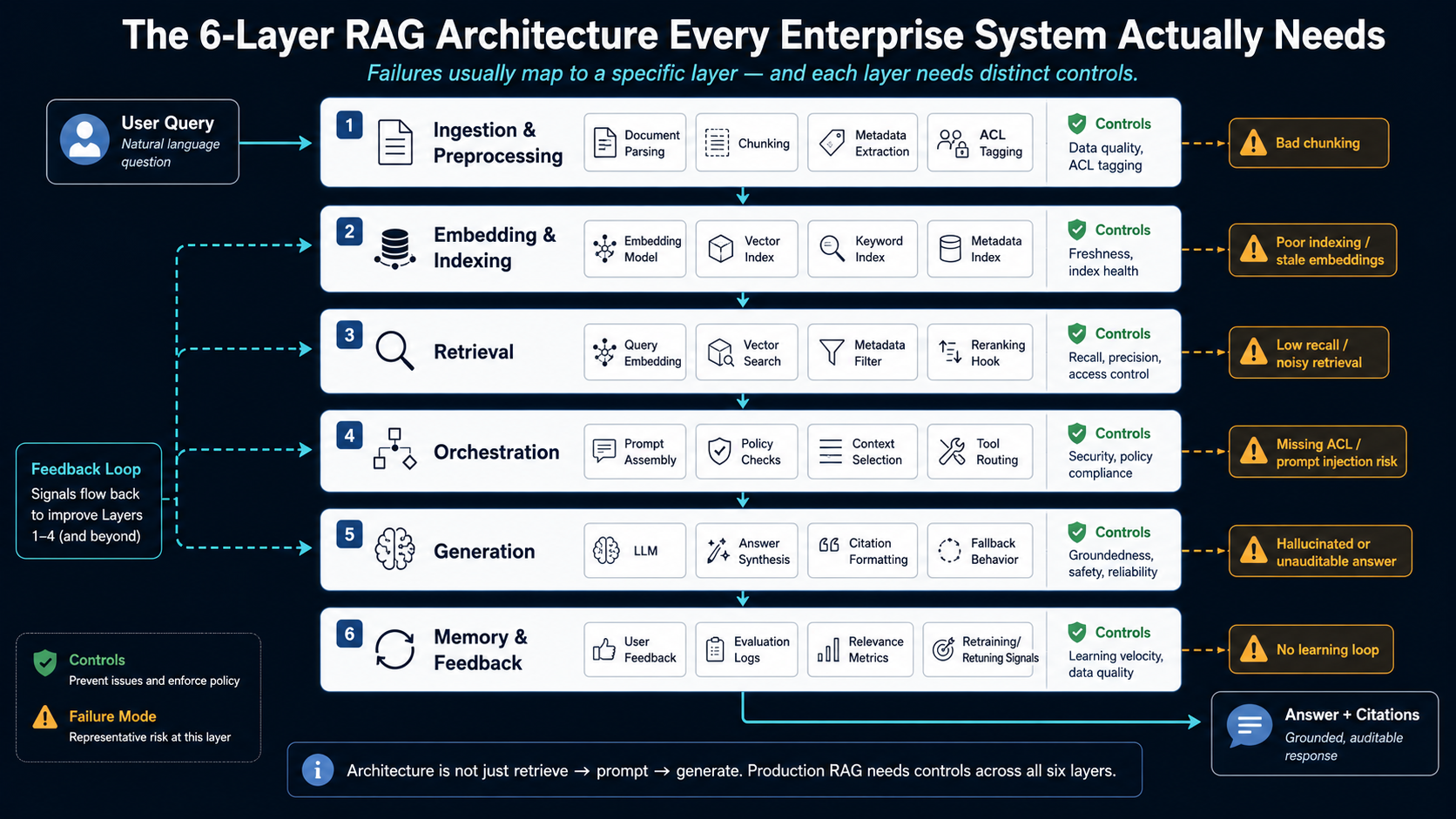
The challenge is not knowing every possible RAG technique. It is knowing which problem you are actually trying to solve, which architectural capability addresses it, when the added complexity is worth the cost, and what to measure before moving to a more advanced design. Below is the same six-layer model, but with the implementation decisions made explicit at each layer - the parameters, algorithms, and tradeoffs a team actually has to choose between.
Click to enlarge
The core loop, end to end
Every production RAG system is a variation of the same five-step sequence. The query is embedded using the same model used at index time - a mismatch here silently degrades recall. Candidates are retrieved with access control applied at query time as a pre-filter, not after the fact. The candidate set is reranked and compressed to a token budget before anything reaches the model. The model generates a response against explicit grounding instructions. And every interaction - query, candidates, reranked results, response - is logged so failures can be diagnosed at their source later.
Most production failures trace back to a shortcut taken at one of these five steps. The layers below explain what each step actually requires.
The six responsibilities
Ingestion and preprocessing converts source content into units that can be reliably searched. The decisions here set the quality ceiling for everything downstream, and they are concrete: chunk size, chunk overlap, and parser fidelity.
- Fixed-size chunking (512-1024 tokens with 10-15% overlap) is the simplest baseline and works for homogeneous text. Recursive character splitting respects paragraph and sentence boundaries before falling back to hard splits.
- Semantic chunking - splitting at points where consecutive sentence embeddings diverge past a similarity threshold - produces more coherent units for heterogeneous documents but costs an embedding pass at ingestion time.
- Layout-aware parsing matters more than chunking strategy for enterprise content. Tools like
unstructured.ioor Azure Document Intelligence preserve table structure and reading order from PDFs; naive text extraction silently scrambles multi-column layouts and table cells. - Every chunk should carry metadata at write time, not be backfilled later:
doc_id,source_uri,acl_tags,version_hash,ingested_at. Content hashing (SimHash or MinHash) at this stage catches near-duplicate documents before they pollute the index.
Embedding and indexing converts processed content into searchable representations. Two decisions dominate: which embedding model, and which index structure.
- Embedding model choice trades dimensionality, cost, and domain fit: OpenAI's
text-embedding-3-large(3072 dims, configurable down via dimension truncation), Voyage AI'svoyage-3(strong on retrieval benchmarks, supports input-type-aware encoding for queries vs. documents), or open-weight options like BGE-M3 for self-hosted deployments where data residency matters. - Index structure depends on scale. HNSW (Hierarchical Navigable Small World graphs) is the default for sub-10M vector corpora - tunable via
M(graph connectivity, typically 16-64) andef_construction(build-time search depth, typically 100-200), trading index build time and memory for recall. IVF-PQ (inverted file index with product quantization) compresses vectors for billion-scale corpora at some recall cost. - Hybrid indexing - combining sparse lexical search (BM25 via OpenSearch/Elasticsearch) with dense vector search - catches exact-match terms (product codes, error strings, names) that embeddings frequently miss. Fusion happens via Reciprocal Rank Fusion (RRF) rather than naive score averaging, since BM25 and cosine similarity scores are not on comparable scales.
- Access control belongs here, not as a post-filter. Storing ACL tags as indexed metadata and applying them as a pre-filter on the vector search call (Pinecone, Weaviate, and Qdrant all support this natively) prevents the system from ever surfacing a passage to a user who should not see it, even transiently in a reranking step.
Retrieval converts a user's request into a ranked set of candidate evidence. Its output quality is bounded entirely by what the first two layers prepared, but retrieval itself has tunable parameters worth getting right: top_k (over-retrieve relative to what you will actually send to the model - pulling 20-25 candidates to rerank down to 5-8 is standard), and the similarity metric (cosine similarity for normalized embeddings, dot product when magnitude carries signal, L2 distance for certain clustering-derived spaces). Query embedding must use the identical model and preprocessing as document embedding - a mismatch here silently degrades recall without throwing an error.
Context orchestration decides what the model is actually allowed to see. This is where most of the engineering effort in a mature system concentrates:
- Deduplication and diversity: Maximal Marginal Relevance (MMR) re-scores candidates to penalize redundancy, balancing relevance against information diversity via a lambda parameter (typically 0.5-0.7).
- Reranking: cross-encoder models (Cohere Rerank, BAAI's
bge-reranker-large) score query-passage pairs jointly rather than via independent embeddings, consistently improving precision at the cost of latency - this is why retrieval over-fetches and reranking narrows. - Compression: techniques like LLMLingua or extractive sentence-level compression reduce token count while preserving the spans the answer depends on, rather than truncating by position.
- The goal is the smallest sufficient evidence set, enforced against an explicit token budget, not the largest possible one.
Generation converts selected evidence into a response. Grounding is a prompting and structural discipline, not a side effect of having context in the prompt. The model must be explicitly instructed to answer only from the provided context, to cite the source passage for each claim, and to state explicitly when the context is insufficient rather than inferring an answer. Faithfulness failures - fluent answers unsupported by the retrieved evidence - happen when these instructions are absent or when the model is allowed to blend retrieved context with parametric knowledge silently. Citation-tagging each claim to a passage ID, enforced at the prompt level, is what makes faithfulness auditable after the fact.
Evaluation, memory, and feedback turns a static pipeline into an observable, improvable system. Concretely, this means logging and scoring on a recurring cadence:
- RAGAS-style metrics: faithfulness (is the answer supported by retrieved context), answer relevancy, context precision (are retrieved passages actually relevant), and context recall (did retrieval surface everything needed).
- Retrieval-level logging: which candidates were retrieved, their similarity scores, which survived reranking, and which were ultimately cited - this is what lets a failure get traced back to ingestion, indexing, or retrieval rather than blamed on "the model."
- Feedback signals (explicit thumbs up/down, implicit reformulation patterns) feed back into chunking adjustments, reranker fine-tuning, or targeted re-indexing - closing the loop rather than treating the pipeline as fixed after launch.
How the series is structured
Each subsequent part introduces a capability that addresses a specific, observable failure, with the same pattern: start with the simplest system that could work, measure it against real questions, identify the specific gap, and add exactly the capability that closes it - with the implementation detail to go with it.
Part 2 covers naive RAG - the simplest useful baseline and the right starting point for almost every system. Part 3 introduces advanced retrieval techniques when the basic pipeline retrieves the wrong evidence. Part 4 covers routing and graph-based retrieval for questions that require different sources or relationship traversal. Part 5 covers agentic and iterative retrieval for questions that require multiple dependent steps. Part 6 brings the patterns together as a practical decision guide.
The more advanced patterns do not replace this core architecture. They add components inside these six layers. Every addition has an obvious home once you understand the foundation.
Quick layer audit: what does your pipeline cover?
Check every layer you have deliberately implemented. Unchecked ones are the most likely source of current failures.
The rule that runs through the series: start simple, measure the failure, add the capability that fixes it. Do not choose an architecture because it sounds advanced. Choose it because your current system has a specific, measured problem.
RAG Architecture Series - 6 Parts