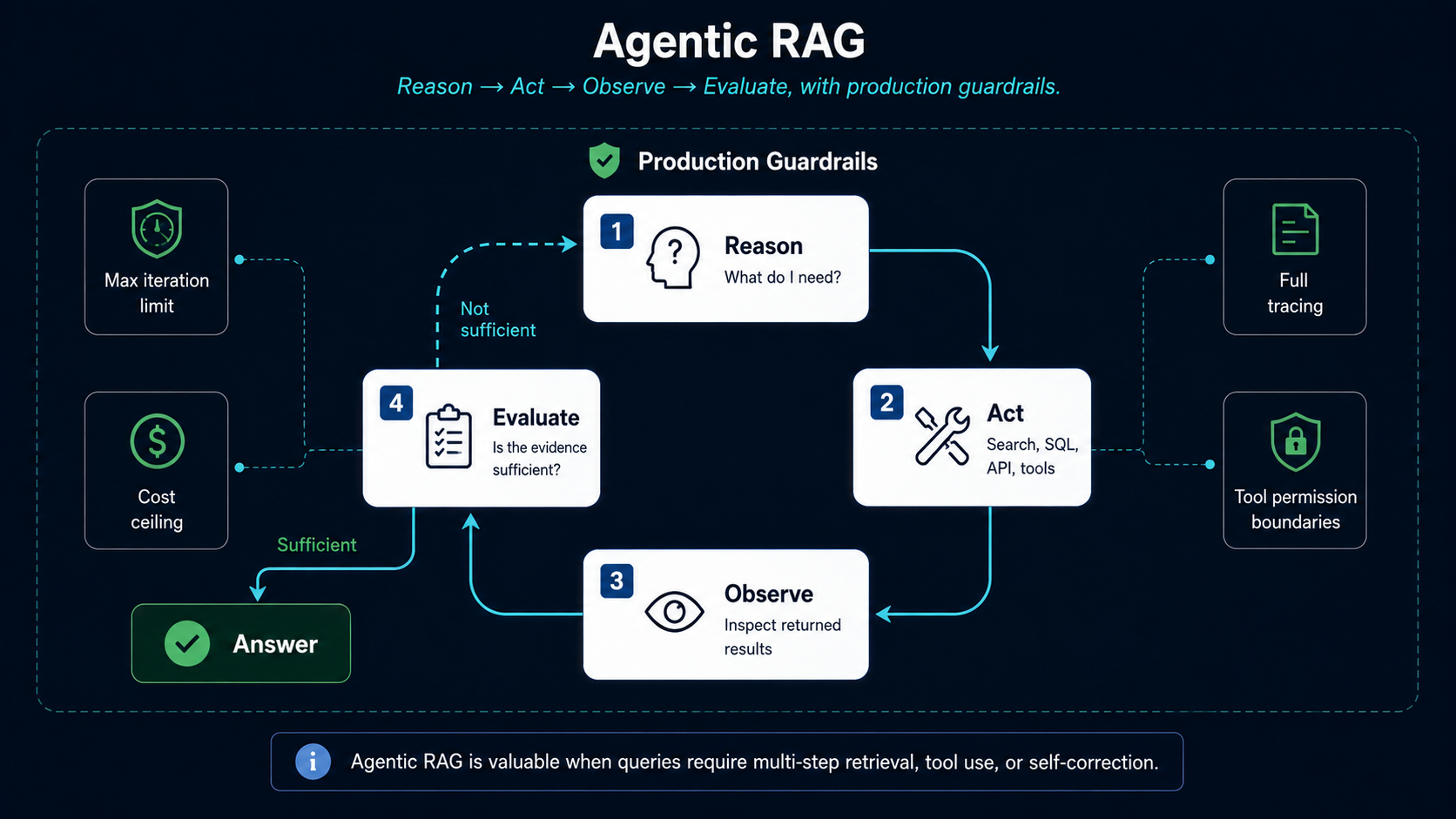
Some questions cannot be answered through a single retrieval pass. The system may need to create a plan, select a source or tool, retrieve evidence, inspect what it found, refine the next step, and stop when the evidence is sufficient.
Everything in Parts 1 through 4 describes a fixed pipeline: a predetermined sequence of steps executed once per query. Agentic and iterative RAG breaks that assumption - the system adapts its retrieval strategy based on what it discovers along the way.
Click to enlarge
The iterative retrieval loop
The core pattern has six steps. The system first creates a plan based on the question - identifying what information is needed and in what order. It then selects a source or tool appropriate to the first step. It retrieves evidence from that source. It inspects what it found, evaluating whether the result is relevant, sufficient, or contradictory. Based on that inspection, it refines the next step - which may involve a different query, a different source, or a different tool entirely. Finally, it stops when the accumulated evidence is sufficient to answer the question.
The stopping condition is the most important design element. Without an explicit criterion for sufficiency, the system has no mechanism for deciding when it has found what it needs. The result is not an agent - it is an infinite retry loop.
When to use it
Iterative retrieval earns its complexity when four conditions apply. The next search depends on an earlier result - the answer to one question determines what to ask next. Several tools must be used in sequence - not just a single vector index but structured databases, APIs, or external search. The system must compare, investigate, or verify - answering a question requires synthesizing evidence from multiple distinct retrievals. Or a fixed retrieval pipeline cannot anticipate every path - the question space is too varied for a predetermined retrieval sequence to cover.
What it adds
Every iteration adds latency. Every tool call adds cost. Every step introduces state that must be tracked across the loop. And every additional action creates more opportunities for the system to loop indefinitely, drift from the original question, or choose an unsafe action. These are not theoretical risks - they are the operational realities that make agentic systems harder to run reliably than fixed pipelines.
The non-determinism problem
Unlike a fixed pipeline, an agentic system can take different paths through the same question on different runs. The planning step may decompose the query differently. The tool selector may choose a different source. An intermediate retrieval may surface a different passage, redirecting every subsequent step. This is not a bug - it is what makes the pattern useful for complex questions. But it means you cannot test an agentic system the way you test a fixed pipeline. You cannot assert that a specific set of passages was retrieved, because the retrieval path is not deterministic. Meaningful testing requires evaluating output quality across multiple independent runs of the same question and checking whether the distribution of answers is acceptable - not asserting a single correct trace. A test that passes once is not a signal.
State management follows from this directly. Each iteration produces retrieved passages, intermediate conclusions, and tool outputs that subsequent steps must reason over. How that state is represented and bounded - what persists, what is summarized, what is discarded - determines whether the system reasons coherently across steps or accumulates noise that degrades later decisions.
What production systems require
Four controls are non-negotiable before an agentic retrieval loop goes to production. A hard maximum iteration limit prevents the system from running indefinitely when it cannot find a satisfying answer. A cost ceiling prevents runaway tool-call spending on a single query. Full execution tracing records every decision, tool call, retrieved passage, and intermediate result, so failures can be diagnosed rather than observed. And validated tool permissions constrain what the system is allowed to do - not every tool should be accessible for every query type.
These are not hardening steps to add later. They are part of the minimum viable architecture for any system that can take actions based on what it retrieves.
Is your system ready for agentic retrieval?
Five prerequisites. Skipping any one of them produces a system you cannot debug or trust in production.
Remember: agentic RAG is not a model searching freely until it feels finished. It is a controlled retrieval workflow with inspectable decisions, hard limits, and clear stopping conditions.